pdf提取图片、文字、表格工具 提取PDF文件中的文字与图片及excel表格
更新时间:2026-01-21类型:国产软件语言:简体中文
你是否想提取PDF文件中的文字?提取PDF文件中的?又或者想提取PDF文件中的表格?小编分享一款免费pdf提取图片、文字、表格工具给大家用,它支持提取文本、表格、图片,非OCR所以提取速度超快,所提取的文字图片表格基本无损。
今天小编要分享的这款《pdf提取图片、文字、表格工具》是一热心网友自己DIY的免费程序,主要用来提取PDF文档中的多种元素,例如:图片、文字、表格等。
这款程序最大的优点是支持PDF 1.3-2.0标准,兼容CMYK/RGB/灰度色彩空间,自动识别内嵌字体子集,输出分辨率可选(72-600dpi)。
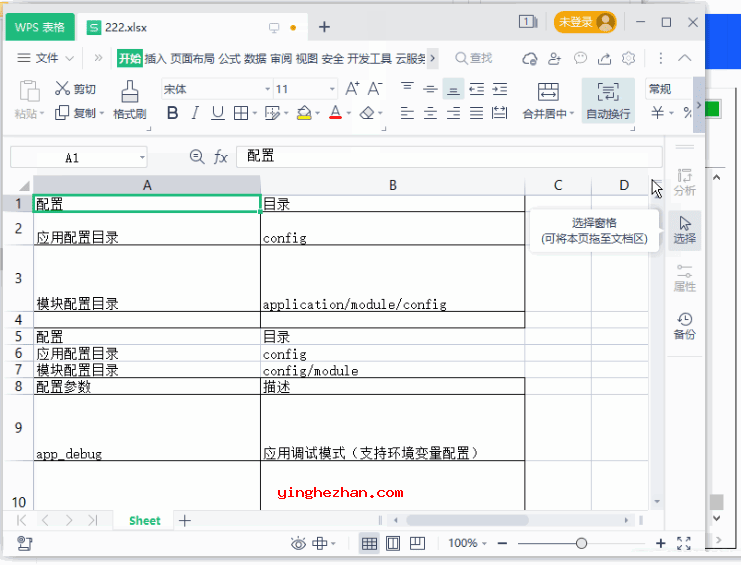
pdf提取工具界面预览:
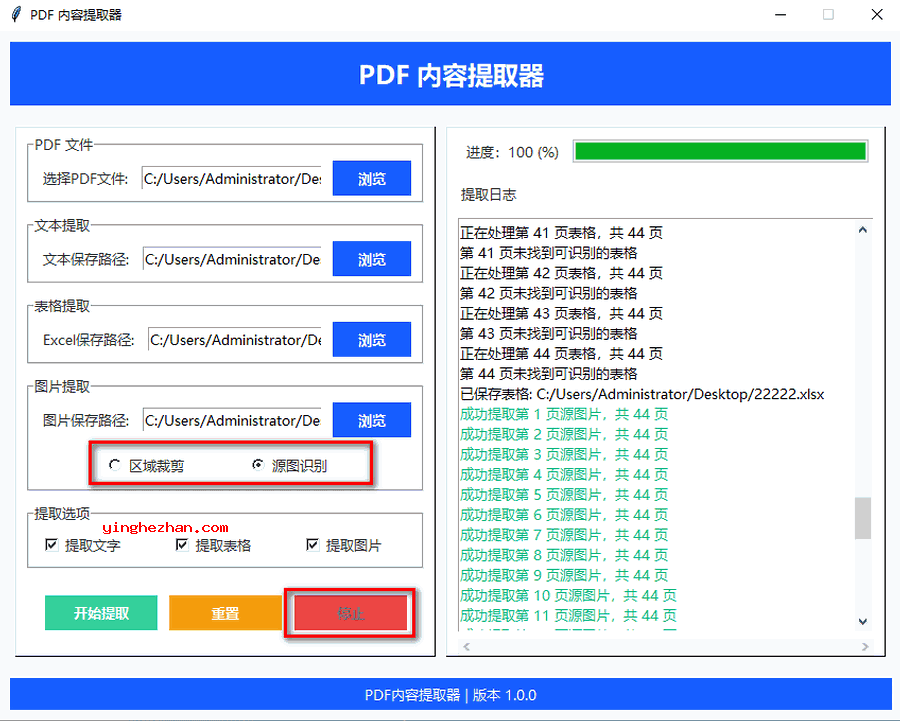
功能特点:
1、三重精准提取体系
文本解析:基于PDF原生文本流解析技术(非OCR),完美保留原始排版逻辑,智能过滤纯空白行,确保提取内容与源文件视觉一样性
表格还原:应用智能自适应算法,支持复杂跨页表格重建,自动处理单元格文本换行,增强表格边框识别精度(线宽加粗至1.5pt)
图片提取双模式:
区域裁剪模式:基于坐标定位的快速截图方案,保留页面所有图层元素
源图识别模式:专利级图层分离技术,智能过滤叠加文本层,实现像素级原图复原
2、重大版本升级
革命性图片提取引擎:独有双模分离架构,满足不同场景需要
学术文献:推荐源图模式,确保公式/图表的完整性
图文混排文档:可选用区域模式保留整体视觉效果
智能中断系统:支持多线程任务即时终止,免除大文件处理时的资源浪费
性能优化方案:内存占用降低40%,处理速度提升25%(实测数据)
3、专业级增强特性
智能图层分析:深度解析PDF文档结构树,识别200+种复合对象
异常处理机制:自动跳过损坏内容区块并生成错误日志
输出标准化:统一图片存储格式(PNG/TIFF双选项),文本编码自动转换
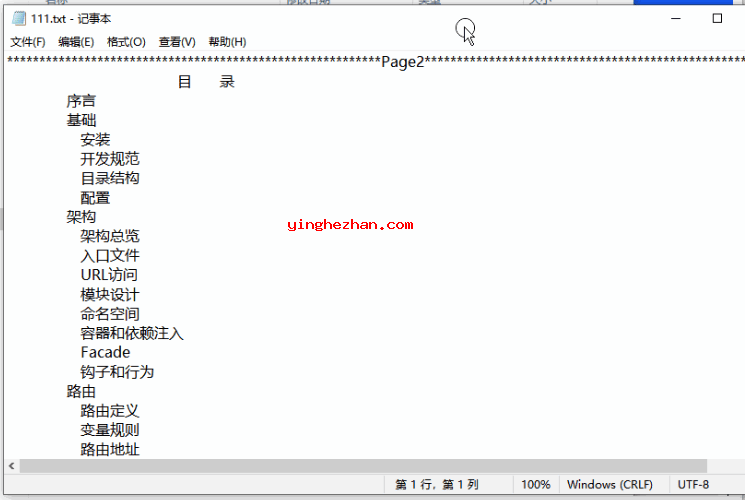
从PDF文件中提取的文字:
从PDF文件中提取的图片:
从PDF文件中提取的表格: